
ASEEC lab has broad research interests in hardware security and trust, big data computing, and heterogeneous processor and memory architectures design and optimization. Our overall goal is to develop a secure and energy-efficient computer system. For the long-term, the greatest challenge continues to be that the underlying implementation technology, as well as new applications power, performance, and security requirements, affect computing system architecture design. In our research, we are therefore interested in addressing the two major challenges of security and energy-efficiency that the computer design industry is facing, particularly in emerging application domains such as big data analytics, IoT, biomedical computing, and wearable imaging and vision. The overarching theme of ASEEC lab research is to better architect computer systems for Secure and Sustainable Computing in presence of security and energy-efficiency challenges. This can only be achieved by addressing these challenges at various levels of abstraction, from software and application levels to run-time system, architecture and even circuit and technology levels. This necessitates forming strong collaborative bonds with other disciplines such as computer vision, machine learning, data mining, biomedical engineering, telecommunication, and cybersecurity and undertaking multi-disciplinary research projects. The outline of ASEEC lab major research achievements and future research plan are as follows:

AI-Based Stress Detection
We use the state-of-art machine learning algorithms to discriminate stress into 1) acute threat, 2) potential threat and 3) sustain threat. We propose a machine learning framework Machine Learning Pipe as shown in Figure. In the proposed framework, the measured data are first pre-processed to remove undesirable data and to balance the data. Afterwards, a comprehensive feature work will be conducted on the cleaned data including feature extraction, dimension reduction and feature selection. The feature extraction is comprehensive that over 300 features are extracted in both time-domain and frequency-domain. Then, manifold dimension reduction method is applied in order to map 300+ dimension into lower and more informative dimension and Chi-square feature selection method is used to further improve the set of features. Cross-validation is then used is to repeatedly use the data, segment the sample data, and combine them into different training sets and test sets to prevent overfitting. Finally, three state-of-art machine learning algorithms are applied consist of Adaboost, Recurrent Neural Networks and Support Vector Machine. In the end, a receiver operating characteristic curve (ROC Curve) and Precision-Recall Curve (PR Curve) are generated to evaluate the diagnostic performance and confidence of the machine learning model. Besides, the confusion matrix is also generated in which accuracy, precision, recall and F-1 score can be easily calculated. In addition, features are ranked according to evaluation results and the feature rank is looping back to step 4: dimension reduction and feature selection and influence the results of feature choice.

Machine Learning-Based Hardware Trojan Detection
The security and trustworthiness of Application Specific Integrated Circuits (ASICs) are exacerbated by the modern globalized semiconductor business model. This model involves many steps performed at multiple locations by different providers and integrates various Intellectual Properties (IPs) from several vendors for faster time-to-market and cheaper fabrication costs. With more emphasis on security in hardware design, it is critical that all security concerns from foundries are appropriately evaluated and mitigated. In the ASEEC lab - ASIC cohort, we focus on hardware security and supply chain security of Integrated Circuits (ICs) and intellectual property (IP) blocks. Countermeasures and mitigation solutions to Hardware Security threats such as Hardware Trojans (HTs), Side-Channel attacks, IP theft, IC piracy, and counterfeiting, have been developed at the ASEEC lab. LUT-based logic-locking, machine learning-based HT detection, and side-channel attack mitigation using CMOS and STT-MRAM devices have been proposed and presented at relevant conferences. A prototype chip to showcase our Hardware Security research was successfully taped-out in TSMC 65nm. Work in this area had led to several conference papers in DAC 2021 (2-papers accepted), DAC 2022 (2-papers accepted), ICCAD 2019, DATE 2020, ICCD 2020, GLSVLSI 2021, a submission to ISSCC 2021, and journal publications in ACM TODAES 2022 and ACM TECS 2023.

Improving Firmware Analysis Tools for Bare-metal Embedded Devices
From the sophisticated medical equipment in hospitals and robotic control systems in manufacturing plants and national defense infrastructure, to the smart devices in our homes that recognize and assist us in our daily routines, bare-metal embedded systems are oft unrecognized yet critical components of the technologies that have come to define modern society. As a consequence, a security breach of one of these systems can potentially have severe adverse effects at both the individual and national level. Of particular concern are firmware vulnerabilities, which when left unaddressed can expose devices to a host of possible attacks, ranging from eavesdropping to full-on hijacking. Despite the obvious danger, firmware security has lagged far behind traditional software security and remains woefully lacking in many real-world systems. This is in large part due to the inherent difficulty of analyzing embedded firmware, as firmware is tightly coupled to its target hardware system. The resulting hardware platform diversity and functional dependence on external peripheral devices makes many traditional methods of software analysis much more difficult to implement on firmware.
Nonetheless, significant effort has been made to bring cutting-edge software vulnerability detection and program analysis techniques to firmware in the past decade. Yet many of the tools that have arisen as a result of these advances have failed to find widespread adoption in industry due to their prohibitively high learning curve. In order to encourage a paradigm shift towards secure-by-design firmware development and testing, we aim to advance the edge of research in bare-metal firmware security by developing static and dynamic analysis tools that are practical and accessible for developers and security auditors alike. In the static domain, we focus on leveraging graph learning techniques on control flow graphs for binary similarity analysis, which auditors can use to assess the risk of software supply chain attacks by isolating the presence of 3rd party libraries and APIs that a firmware image might be dependent on. In the dynamic domain, we are focused on automating and improving existing firmware fuzzing techniques, from instrumentation and rehosting, to root cause analysis, in the hopes of tightening security feedback loops for developers.

Co-Location Attacks in Multi-Tenant Clouds
Cloud computing has emerged as a critical part of commercial computing infrastructure due to its computing power, data storage capabilities, scalability, software/API integration, and convenient billing features. It has been proven that heterogeneity in the cloud, where a variety of machine configurations exist, provides higher performance and power efficiency for applications. This is because heterogeneity enables applications to run in more suitable hardware/software environments. In recent years, the adoption of heterogeneous cloud has increased with the integration of a variety of hardware into cloud systems to serve the requirements of increasingly diversified user applications. At the same time, the emergence of security threats, such as micro-architectural attacks, is becoming a more critical problem for cloud users and providers. In this project, we focus on the cloud scheduler level and explore how the important prerequisite of micro-architectural attacks, co-location of victim and attacker instances, can be achieved and how the security vulnerability can be quantitatively measured.

Smart Pain Management Ecosystem
Pain is an unpleasant sensory and emotional experience affecting the quality of life of patients. Severe pain is common throughout the disease trajectory of cancer. Such pain has been reported in over half of patients [1]. Overtreatment of pain may result in nausea, vomiting, or constipation immediately and drug addiction in the long term while undertreatment of pain may lead to physical and mental suffering. However, Pain is subjective and hard to evaluate. For now, pain is assessed by self-report approaches such as the visual analog scale (VAS) or by the professional clinician which is time-consuming and subjective. In addition, successful pain management requires continuous pain assessment to avoid undertreatment or overtreatment since pain is dynamic. Thus, it is necessary to have an objective, accurate, continuous pain assessment method. Besides pain assessment, effective pain treatment is another important component of a successful pain management system. Neurostimulators, also known as Transcutaneous Electrical Nerve Stimulation (TENS) devices, are found as a safe and effective way of managing pain. Using a no-obnoxious electrical charge within FDA-safe ranges stimulates the nonpain related nerves around painful locations and therefore, mitigates pain. We are developing a neurostimulation wearable ecosystem that utilizes objective neurophysiological pain proxies to interpret pain levels and provide appropriate neural stimulation. This work has led to four conference publications in IEEE EMBC 2022, IEEE BIME 2022.

Closing FPGA Power Side-channels in the Modern Cloud Computing Paradigm
The cloud computing paradigm has enabled access to previously unimaginable compute capabilities for desktops, mobile phones, resource constrained embedded systems at the IoT edge, and several other pervasive technologies. Cloud users expect data privacy in a wide variety of heterogeneous computing scenarios. FPGAs provide unmatched flexibility and customization capabilities at a significantly lower cost than many ASIC implementations. However, this flexibility introduces a massive attack surface that remote adversaries can leverage to extract sensitive cloud user data through power side-channels. To develop an adaptive defense, we utilize the same attack primitives used in remote power side-channel attacks to, instead, defeat potential adversaries. Using machine learning we guide real-time active noise injection modules to significantly reduce the quality of sampled power distribution network measurements. We are currently developing a novel active noise injection scheme which leverages architecture-agnostic FPGA modules to close side-channels before attackers can extract valuable user data from cloud instances. While our work focuses primarily on Intel FPGA devices, we avoid the use of vendor IPs such that our proposed defense can be reused on devices from all leading FPGA vendors. Additionally, we eliminate the need for coordination with cloud service providers by restricting our solution to use only modules that are not prohibited by the leading cloud vendors. In this manner, we enable cross-platform cross-CSP adaptive power side channel defense in FPGA cloud platforms.
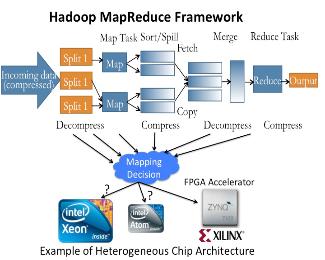
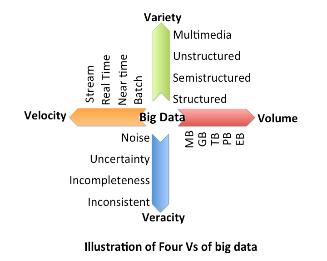
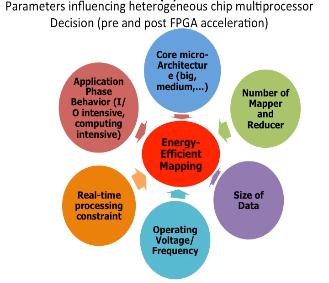
Hardware Accelerated Mappers for Hadoop MapReduce Streaming
Heterogeneous architectures have emerged as an effective solution to address the energy-efficiency challenges. This is particularly happening in data centers where the integration of FPGA with general-purpose processors introduces enormous opportunities to address the power, scalability and energy-efficiency challenges of processing emerging applications, in particular in domain of big data. Therefore, the rise of hardware accelerators in data centers raises several important research questions: What is the potential for hardware acceleration in MapReduce, a defacto standard for big data analytics? What is the role of processor after acceleration; whether big or little core is most suited to run big data applications post hardware acceleration? This work answers these questions through methodical real-system experiments on state-of-the-art hardware acceleration platforms. We developed the MapReduce implementation of K-means, K nearest neighbor, support vector machine and naive Bayes in a Hadoop Streaming environment that allows developing mapper functions in a non-Java based language suited for interfacing with FPGA. We present a full implementation of the HW+SW mappers on existing FPGA+core platform. Moreover, we study how various parameters at the application, system and architecture levels affect the performance and power-efficiency benefits of Hadoop streaming hardware acceleration. Results suggest that HW+SW acceleration yields significantly higher speed up on little cores and higher power reduction benefits on big cores, reducing the performance and power gap between the two after the acceleration. Overall, the experimental results show that a low cost embedded FPGA platform, programmed using a semi-automated HW+SW co-design methodology, brings significant performance and energy-efficiency gains for Hadoop MapReduce computing. This work has led to four conference publications in IEEE/ACM CODES-ISSS 2016, IEEE Big Data 2015, FCCM 2015, CCGRID 2015, and two journal submissions under review at IEEE Transactions on Multi-Scale Computing Systems, and Elsevier Journal of Parallel and Distributed Computing.
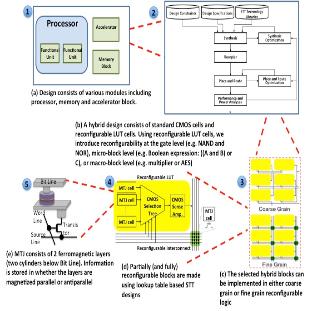
Logical Vanishability through Hybrid Spin Transfer Torque-CMOS Technology to Enhance Chip Security
The horizontal IC supply chain which involves several steps performed at multiple locations by different providers and integrates various IPs from several vendors has become prevalent due to confluence of increasingly complex supply chains, time-to-market delivery, and cost pressures. This trend, poses significant challenges to hardware security assurance including design cloning, overproduction and reverse engineering. In possession of detailed design implementation at the physical level, an untrusted foundry may overproduce the design without design-house permission. After design release to the market, the design can also be subject to non-invasive reserve engineering, such as side channel attacks to obtain secret information during design operation or invasive reserve engineering to obtain detailed design implementation. In order to prevent design reverse engineering this research introduces the concept of vanishable design. We introduce a logical vanishing design based on hardware re-configuration by employing highly promising Spin Transfer Torque Magnetic technology (STT) to build Look-Up-Tables (LUTs) logic components. The STT reconfigurable design is similar in functionality to an FPGA but with significantly higher speed running at GHz frequency, near zero leakage power, high thermal stability, highly integratable with CMOS and more secure against various physical attacks, and overall competitive with custom CMOS design in terms of performance and energy-efficiency. Our proposed design flow integrates STT and CMOS technologies such that the final design implementation is hidden from any untrusted party been involved in the IC supply chain. Furthermore, the design effectively stands destructive reverse engineering attacks and non-invasive side-channel attacks. This work has led to several conference publications in DAC 2016, ICCD 2016, SOCC 2016, ISCAS 2016, ISQED 2016, DATE 2014, and GLSVLSI 2014, and two journal publications in Elsevier Microelectronics Reliability Journal and IEEE CAL 2014, and one journal submission to ACM TODAES.
Co-Locating and Concurrent Fine-Tuning MapReduce Applications for Energy Efficiency
Fine-tuning configuration parameters of MapReduce applications at the application, architecture, and system levels plays a crucial role in improving the energy-efficiency of the server and reducing the operational cost. In this work, through methodical investigation of performance and power measurements, we demonstrated how the interplay among various MapReduce configurations as well as application and architecture level parameters create new opportunities to co-locate MapReduce applications at the node level. We also showed how concurrently fine-tuning optimization parameters for multiple scheduled MapReduce applications improves energy-efficiency compared to fine-tuning parameters for each application separately. In this work, we present Co-Located Application Optimization (COLAO) that co-schedules multiple MapReduce applications at the node level to enhance energy efficiency. Our results show that through co-locating MapReduce applications and fine-tuning configuration parameters concurrently, COLAO reduces the number of nodes to execute MapReduce applications by half while improving the EDP by 2X on average, compared to fine-tuning applications individually and run them serially. This work has led to a conference publication in IEEE IISWC 2017, and a submission to ACM/IEEE ISCA 2018.

Hadoop Characterization for Performance and Energy Efficiency Optimizations on Microservers
The traditional low-power embedded processors such as Atom and ARM are entering into the high-performance server market. At the same time, big data analytics applications are emerging and dramatically changing the landscape of data center workloads. Numerous big data applications rely on using Hadoop MapReduce framework to perform their analysis on large-scale datasets. Since Hadoop configuration parameters as well as system parameters directly affect the MapReduce job performance and energy-efficiency, joint application, system and architecture level parameters tuning is vital to maximize the energy efficiency for Hadoop-based applications. In this work, through methodical investigation of performance and power measurements, we demonstrated how the interplay among various Hadoop configuration parameters, as well as system and architecture level parameters affect not only the performance but also the energy-efficiency. Our results identified trends to guide scheduling decision and key insights to help improving Hadoop MapReduce performance, power and energy-efficiency on microservers. This work has led to a conference publication in IEEE ISPASS 2016, and a journal publication in IEEE TMSCS 2017.
Big vs Little Core for Energy-Efficient Hadoop Computing
Heterogeneous architectures that combine big Xeon cores with little Atom cores have emerged as a promising solution to enhance energy-efficiency by allowing each application to run on an architecture that matches resource needs more closely than a one-size-fits-all architecture. Therefore, the question of whether to map the application to big Xeon or little Atom in heterogeneous server architecture becomes important. In this work, we characterized Hadoop-based applications and their corresponding MapReduce tasks on big Xeon and little Atom-based server architectures to understand how the choice of big vs little cores is affected by various parameters at application, system and architecture levels and the interplay among these parameters. Furthermore, we have evaluated the operational and the capital cost to understand how performance, power and area constraints for big data analytics affects the choice of big vs little core server as a more cost and energy efficient architecture. This work has led to three conference publications in IEEE DATE 2017, IEEE Big Data 2015, and IEEE ICCD 2015, and a journal submission with Minor Revision to Elsevier Journal of Parallel and Distributed Computing (SLID).
Analyzing Hardware Based Malware Detectors
Detection of malicious software at the hardware level is emerging as an effective solution to increasing security threats. Hardware based detectors rely on Machine-Learning (ML)classifiers to detect malware-like execution pattern based on Hardware Performance Counters(HPC) information at run-time. The effectiveness of these methods mainly relies on the information provided by expensive-to-implement limited number of HPC. This work thoroughly analyzes various robust ML methods to classify benign and malware applications. Given the limited availability of HPC the analysis results help guiding architectural decision on what hardware performance counters are needed most to effectively improve ML classification accuracy. For software implementation, we fully implemented these classier at OS Kernel to understand various software overheads. The software implementation of these classifiers found to be relatively slow with the execution time order of magnitude higher than the latency needed to capture malware at run-time. This is calling for hardware-accelerated implementation of these algorithms. For this purpose, we have synthesized the studied classifiers to compare various design parameters including logic area, power, and latency. The results show that while complex ML classier such as MultiLayerPerceptron are achieving close to 90% accuracy, after taking into consideration their implementation overheads, they perform worst in terms of PDP, accuracy/area and latency compared to simpler but less accurate rule based and tree based classifiers. Our results further show OneR to be the most cost-effective classier with more than 80% accuracy and fast execution time of less than 10ns, achieving highest accuracy per logic area, while relying on only branch-instruction HPC information. This work has led to a publication in DAC 2017 conference and a journal submission to ACM TODAES.

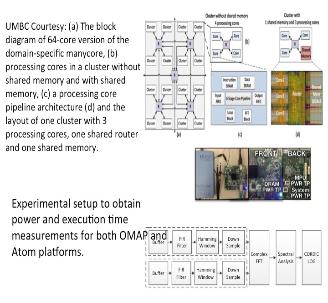
Low Power Architectures for Personalized Biomedical Applications: From General Purpose Processor to Heterogeneous Domain Specific Accelerator
With the rapid advances in small, low-cost wearable computing technologies, there is a tremendous opportunity to develop personal health monitoring devices capable of continuous monitoring of physiological signals. The objective of this project is to build the foundation of the next generation of heterogeneous biomedical signal processing platform that addresses the future generation energy-efficiency requirements and computational demands. In this project, we start with understanding the specific characteristics of emerging biomedical signal and imaging applications on off-the-shelf embedded low power multicore CPU, GPU and FPGA platforms to accurately understand the trade-offs they offer and the bottlenecks they have. Based on these results, we designed and architected a domain-specific manycore accelerator in hardware and integrated it with an off-the-shelf embedded processor that together combine performance, scalability, programmability, and power efficiency requirements for these applications. We evaluated the performance and power efficiency of the proposed platform with a number of real-life biomedical workloads including seizure detection, handheld ultrasound spectral Doppler and imaging, tongue drive assistive device and prosthetic hand control interface. This work has led to several conference publications in GLSVLSI 2016 (Best Paper Award), ISVLSI 2016, ISCAS 2016 (Invited), ICCD 2015, GLSVLSI 2015, ISLPED 2014, ISQED 2013, GLSVLSI 2014 and a journal publication in IEEE TVLSI.

Memory Requirements of Big Data Applications on Commodity Server Class Architectures
The emergence of big data frameworks requires computational resources and memory subsystems that can scale to manage massive amounts of diverse data. Given the large size and heterogeneity of the data, it is currently unclear whether big data frameworks such as Hadoop, Spark, and MPI will require high performance and large capacity memory to cope with this change and exactly what role main memory subsystems will play; particularly in terms of energy efficiency. The primary purpose of this study is to answer these questions through empirical analysis of different memory configurations available for commodity hardware and to assess the impact of these configurations on the performance and energy efficiency of these well-established frameworks. In contrast with recent works that advocate the importance of using high-end DRAM (high bandwidth-capacity) for well-studied applications in Hadoop and Spark frameworks, we show that neither DRAM capacity, frequency, nor the number of channels play a significant role on the performance of all studied Hadoop as well as most studied Spark applications. On the other hand, our results reveal that iterative tasks (e.g. machine learning) in Spark and MPI are benefiting from a high-end DRAM; in particular high frequency and large numbers of channels. Among the configurable parameters, our results indicate that increasing the number of DRAM channels reduces DRAM power and improves the energy-efficiency across all three frameworks. Based on micro-architectural analysis, we anticipate these findings to remain valid in future architectures with higher numbers of cores and larger cache capacities running at higher operating frequencies, thereby disincentivizing the use of high-end memory subsystems, making the more expensive memory configurations superfluous. This work has led to two conference publications in IEEE IISWC 2017, IGSC 2017 (Invited).
Memory Navigation for Modern Hardware in a Scale-out Environment
Scale-out infrastructure such as Cloud is built upon a large network of multi-core processors. Performance, power consumption, and capital cost of such infrastructure depend on the overall system configuration including number of processing cores, core frequency, memory hierarchy and capacity, number of memory channels, and memory data rate. Among these parameters, memory subsystem is known to be one of the performance bottlenecks, contributing significantly to the overall capital and operational cost of the server. Also, given the rise of Big Data and analytics applications, this could potentially pose an even bigger challenge to the performance of cloud applications and cost of cloud infrastructure. Hence it is important to understand the role of memory subsystem in cloud infrastructure. Despite the increasing interest in recent years, little work has been done to understand memory requirements to develop accurate and effective models to predict performance and cost of memory subsystem. Currently there is no well-defined methodology for selecting a memory configuration that reduces execution time and power consumption by considering the capital and operational cost of cloud. In this work, through a comprehensive real-system empirical analysis of performance, we address these challenges by first characterizing diverse types of scale-out applications across a wide range of memory configuration parameters. The characterization helps to accurately capture applications’ behavior and derive a model to predict their performance. Based on the predictive model, we propose MeNa, which is a methodology to maximize the performance/cost ratio of scale-out applications running in cloud environment. MeNa navigates memory and processor parameters to find the system configuration for a given application and a given budget, to maximum performance. Compared to brute force method, MeNa achieves more than 90% accuracy for identifying the right configuration parameters to maximize performance/cost ratio. Moreover, we show how MeNa can be effectively leveraged for server designers to find architectural insights or subscribers to allocate just enough budget to maximize performance of their applications in cloud. This work has led to a conference publication in IEEE IISWC 2017.
Enabling Dynamic Heterogeneity with Elastic Architecture for Parallelism, and Energy-Efficiency
Heterogeneous architectures have emerged as a promising solution to enhance energy-efficiency by allowing each application to run on a core that matches resource needs more closely than a one-size-fits-all core. In this work, an ElasticCore platform is described where core resources along with the operating voltage and frequency settings are scaled to match the application behavior at run-time. Furthermore, a linear regression model for power and performance prediction to guide scaling the core size and the operating voltage and frequency to maximize efficiency is described. Circuit considerations that further optimize the power efficiency of ElasticCore are also considered. Specifically, the efficiency of both off-chip and on-chip voltage regulators is analyzed for the heterogeneous architecture where the required load current changes dynamically at run-time. A distributed on-chip voltage regulator topology is proposed to accommodate the heterogeneous nature of the ElasticCore. The results indicate that ElasticCore on is more than twice energy-efficient compared to the BigLitte architecture. This work has led to one conference publications in IEEE/ACM DAC 2015, and a journal submission in minor revision in IEEE TVLSI.
3D Heterogeneous Memory Architecture for Data Intensive Applications
High fabrication cost per bit and thermal issues are the main reasons that prevent architects from using 3D-DRAM alone as the main memory. In this paper, we address this issue by proposing a heterogeneous DRAM memory subsystem that leverages state-of-the-art advances in 3D memory technology (HMC, HBM, Wide I/O) and integrates them with conventional DDRx memory to combine the performance, density, scalability, modularity, and power-efficiency requirements of the server architecture. To realize this design, this research addresses several research challenges heterogeneous memory subsystems are facing by developing modeling tools and a suite of coordinated algorithms and micro-architectural technologies that exploit application-specific characteristics to design the next generation of efficient memory subsystems for server architecture. This work has led to three publications in ASPDAC 2014, and GLSVLSI 2015, ICCD 2015, and one journal publication in ACM JETC.
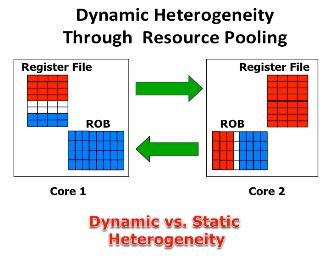
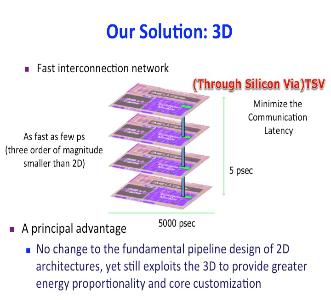
3D Heterogeneous CMP Design
3D die stacking is a recent technological development which makes it possible to create chip multiprocessors using multiple layers of active silicon bonded with low-latency, high-bandwidth, and very dense vertical interconnects. The fast communication network in 3D design, along with the expanded geometry, provides an opportunity to dynamical share on-core resources among different cores. While in a 2D processor, resources (such as register file and instruction queue) available to one core are too distant to ever be useful to another core, with a 3D integration, we can dynamically “pool” resources that are performance bottlenecks for the particular thread running on a particular core. In this research, we introduced an architecture for a dynamically heterogeneous processor architecture leveraging 3D stacking technology. Unlike prior work in 2D, the extra dimension makes it possible to share resources at a fine granularity between vertically stacked cores. As a result, each core can grow or shrink resources as needed by the code running on the core. This architecture, therefore, enables runtime customization of cores at a fine granularity, enables efficient execution at both high and low levels of thread level parallelism, enables fine-grain thermal management, and enables fine-grain reconfiguration around faults. With this architecture, we achieve performance gains of up to 2X, and gain significant advantage in energy-efficiency. This work has led to two publications in HPCA 2012, and DAC 2014.
A Novel Biomechatronic Interface Based on Wearable Dynamic Imaging Sensors
The problem of controlling biomechatronic systems, such as multiarticulating prosthetic hands, involves unique challenges in the science and engineering of Cyber Physical Systems (CPS), requiring integration between computational systems for recognizing human functional activity and intent and controlling prosthetic devices to interact with the physical world. Research on this problem has been limited by the difficulties in noninvasively acquiring robust biosignals that allow intuitive and reliable control of multiple degrees of freedom (DoF). The objective of this research is to investigate a new sensing paradigm based on ultrasonic imaging of dynamic muscle activity. The synergistic research plan will integrate novel imaging technologies, new computational methods for activity recognition and learning, and high-performance embedded computing to enable robust and intuitive control of dexterous prosthetic hands with multiple DoF. The interdisciplinary research team involves collaboration between biomedical engineers, electrical engineers and computer scientists. The specific aims are to: (1) research and develop spatio- temporal image analysis and pattern recognition algorithms to learn and predict different dexterous tasks based on sonographic patterns of muscle activity (2) develop a wearable image- based biosignal sensing system by integrating multiple ultrasound imaging sensors with a low- power heterogeneous multicore embedded processor and (3) perform experiments to evaluate the real-time control of a prosthetic hand. The proposed research methods are broadly applicable to assistive technologies where physical systems, computational frameworks and low-power embedded computing serve to augment human activities or to replace lost functionality. The research will advance CPS science and engineering through integration of portable sensors for image-based sensing of complex adaptive physical phenomena such as dynamic neuromuscular activity, and real-time sophisticated image understanding algorithms to interpret such phenomena running on low-power high performance embedded systems. The technological advances would enable practical wearable image-based biosensing, with applications in healthcare, and the computational methods would be broadly applicable to problems involving activity recognition from spatiotemporal image data, such as surveillance. This research will have societal impacts as well as train students in interdisciplinary methods relevant to CPS. About 1.6 million Americans live with amputations that significantly affect activities of daily living. The proposed project has the long-term potential to significantly improve functionality of upper extremity prostheses, improve quality of life of amputees, and increase the acceptance of prosthetic limbs. This research could also facilitate intelligent assistive devices for more targeted neurorehabilitation of stroke victims. This project will provide immersive interdisciplinary CPS-relevant training for graduate and undergraduate students to integrate computational methods with imaging, processor architectures, human functional activity and artificial devices for solving challenging public health problems. A strong emphasis will be placed on involving undergraduate students in research as part of structured programs at our institution. The research team will involve students with disabilities in research activities by leveraging an ongoing NSF-funded project. Bioengineering training activities will be part of a newly developed undergraduate curriculum and a graduate curriculum under development. The synergistic research plan has been designed to advance CPS science and engineering through the development of new computational methods for dynamic activity recognition and learning from image sequences, development of novel wearable imaging technologies including high-performance embedded computing, and real-time control of a physical system. The specific aims are to: (1) Research and develop spatio-temporal image analysis and pattern recognition algorithms to learn and predict different dexterous tasks based on sonographic patterns of muscle activity. The first aim has three subtasks designed to collect, analyze and understand image sequences associated with functional tasks. (2) Develop a wearable image-based biosignal sensing system by integrating multiple ultrasound imaging sensors with a low-power heterogeneous multicore embedded processor. The second aim has two subtasks designed to integrate wearable imaging sensors with a real-time computational platform. (3) Perform experiments to evaluate the real-time control of a prosthetic hand. The third aim will integrate the wearable image acquisition system developed in Aim 2, and the image understanding algorithms developed in Aim 1, for real-time evaluation of the control of a prosthetic hand interacting with a virtual reality environment. Successful completion of these aims will result in a real-time system that acquires image data from complex neuromuscular activity, decodes activity intent from spatiotemporal image data using computational algorithms, and controls a prosthetic limb in a virtual reality environment in real time. Once developed and validated, this system can be the starting point for developing a new class of sophisticated control algorithms for intuitive control of advanced prosthetic limbs, new assistive technologies for neurorehabilitation, and wearable real-time imaging systems for smart health applications.